
One of the issues we come across during the ETL design is "Update Large Tables". This is a very common ETL scenarion especially when you treat with large volume of data like loading an SCD Type 2 Dimension. We discussed about a design approach for this scenarion in one of our prior articles. Here in this updated article lets discuss a different approach to update Larger tables using Informatica Mapping.
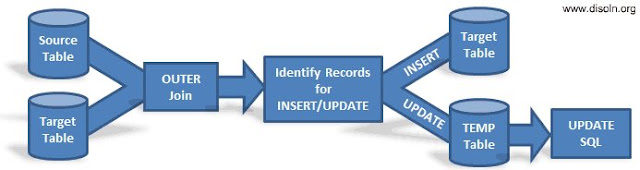
High level Design Approach.
- Use Database JOIN to identify the records to be updated.
- Insert the records into TEMP table, which is identified for UPDATE.
- Use post session SQL to update the target table.
Design Assumption.
- Source and Target tables are relational table.
- Both source and target table is on the same database.
- Tables are accessible using a single database user.
Informatica Implementation.
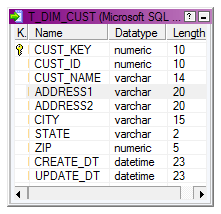
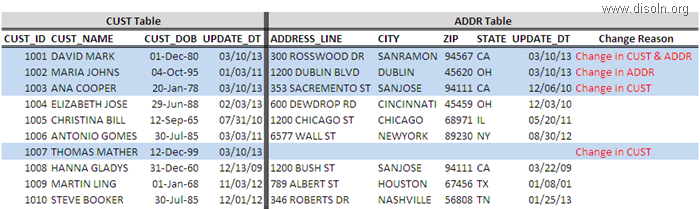
For the demonstration purpose lets consider the Customer Dimension table T_DIM_CUST, which has 100 M records. Each load we are expecting to update 100 K Records records in the Dimension table.
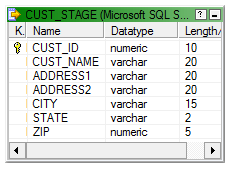
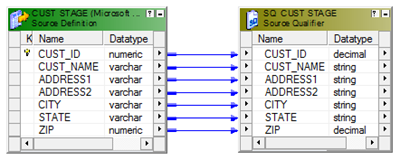
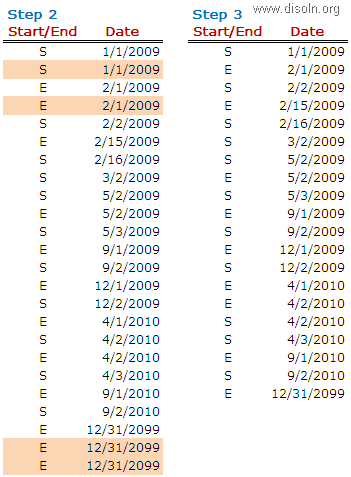
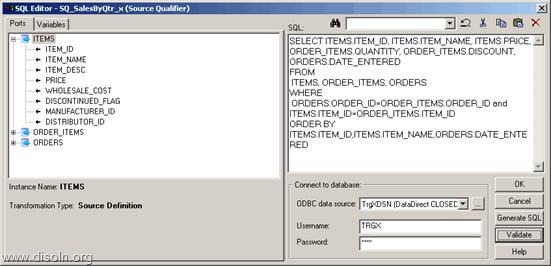
Lets start with the mapping building. As the first step, lets OUTER Join the source table CUST_STAGE and target table T_DIM_CUST. Use the SQL below as the SQL override in source qualifier.
SELECT
--Columns From Source Tables
CUST_STAGE.CUST_ID,
CUST_STAGE.CUST_NAME,
CUST_STAGE.ADDRESS1,
CUST_STAGE.ADDRESS2,
CUST_STAGE.CITY,
CUST_STAGE.STATE,
CUST_STAGE.ZIP,
--Columns from Target Tables.
--If any column from T_DIM_CUST has NULL value, record to be set as INSERT else UPDATE
T_DIM_CUST.CUST_ID,
T_DIM_CUST.AS_OF_START_DT,
T_DIM_CUST.AS_OF_END_DT
T_DIM_CUST.CUST_NAME,
T_DIM_CUST.ADDRESS1,
T_DIM_CUST.ADDRESS2,
T_DIM_CUST.CITY,
T_DIM_CUST.STATE,
T_DIM_CUST.ZIP
FROM CUST_STAGE
--Outer Join is Used
LEFT OUTER JOIN T_DIM_CUST
ON CUST_STAGE.CUST_ID = T_DIM_CUST.CUST_ID
AND T_DIM_CUST.AS_OF_END_DT = TO_DATE('12-31-4000','MM-DD-YYYY')

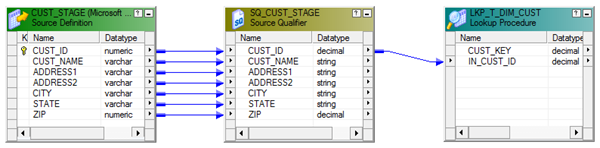
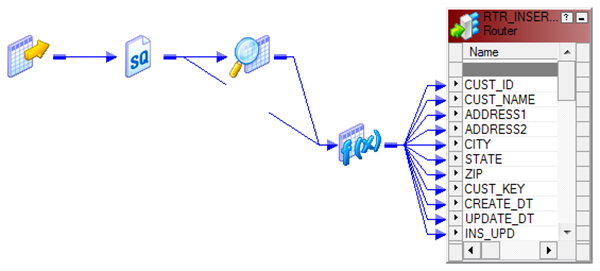
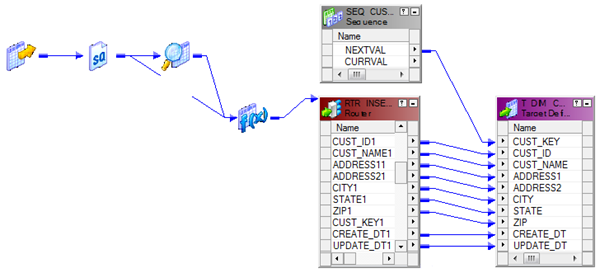
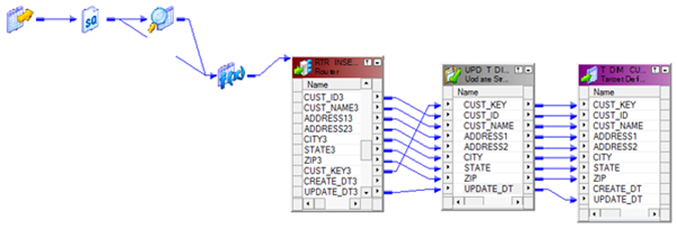
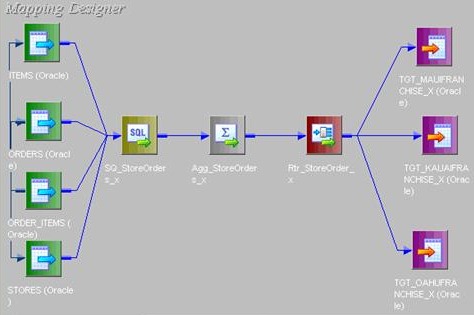
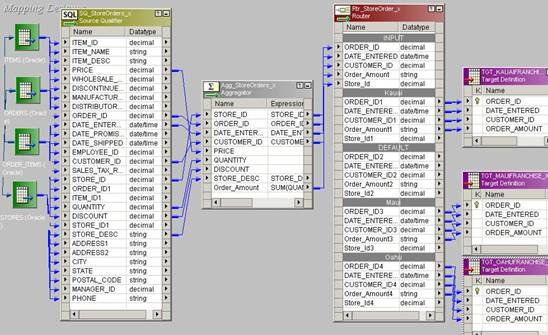
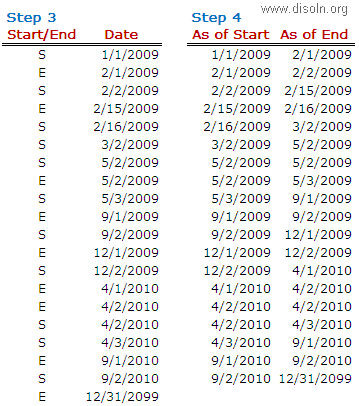
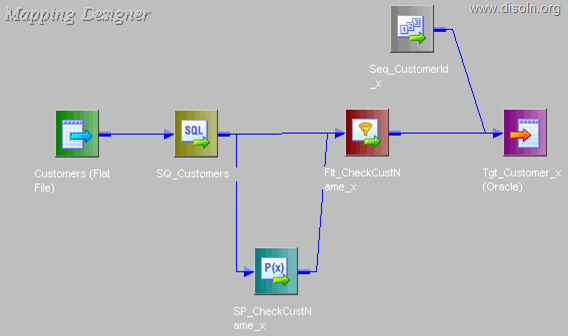
Now using a Router Transformation, route the records to INSERT/UPDATE path. Records identified as INSERT will be mapped to T_DIM_CUST and identified as UPDATE will be mapped to T_DIM_CUST_TEMP.
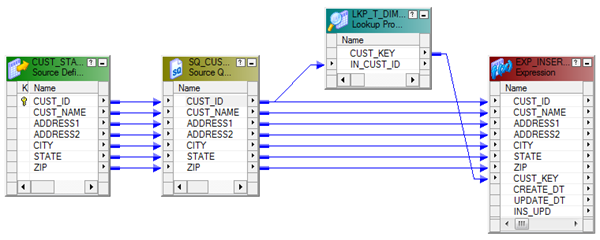
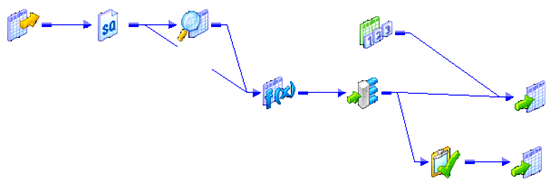
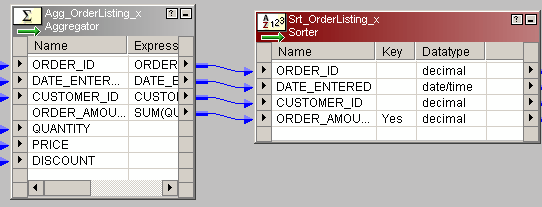
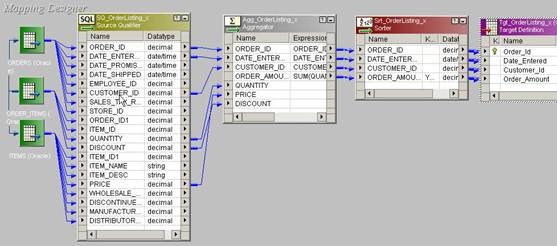
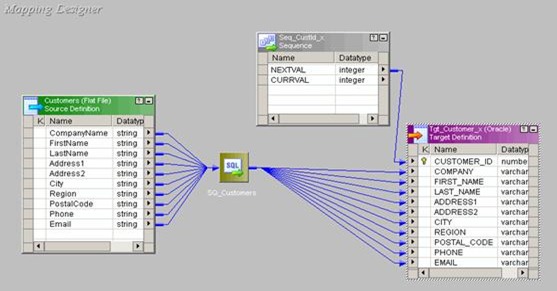
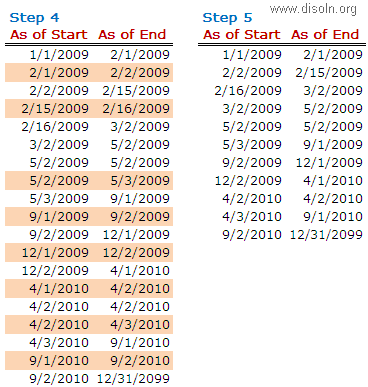
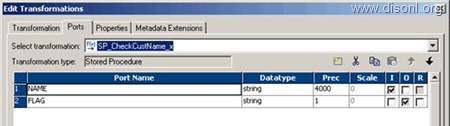
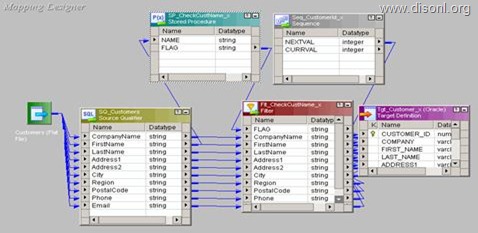
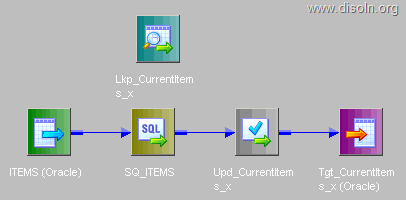
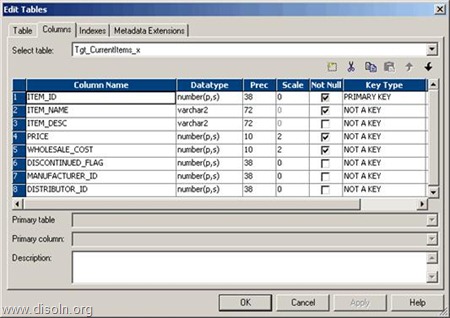
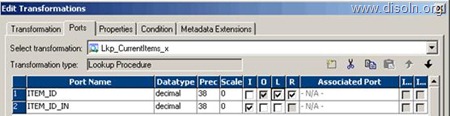
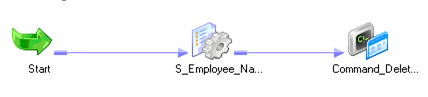
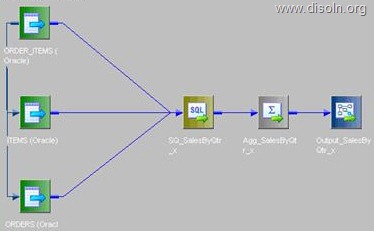
Use T_DIM_CUST_CUST_ID, which is the column from the target table to identify the records to be inserted/updated. If it is NULL, record will be set for insert else record will be set for update. Below is the Router Group Filter Condition and you can see how the mapping looks like in the below image (Below mapping image has not any transformation logic in it).
Use T_DIM_CUST_CUST_ID, which is the column from the target table to identify the records to be inserted/updated. If it is NULL, record will be set for insert else record will be set for update. Below is the Router Group Filter Condition and you can see how the mapping looks like in the below image (Below mapping image has not any transformation logic in it).
- INSERT : IIF(ISNULL( T_DIM_CUST_CUST_ID ), TRUE, FALSE)
- UPDATE : IIF(NOT ISNULL( T_DIM_CUST_CUST_ID ), TRUE, FALSE)

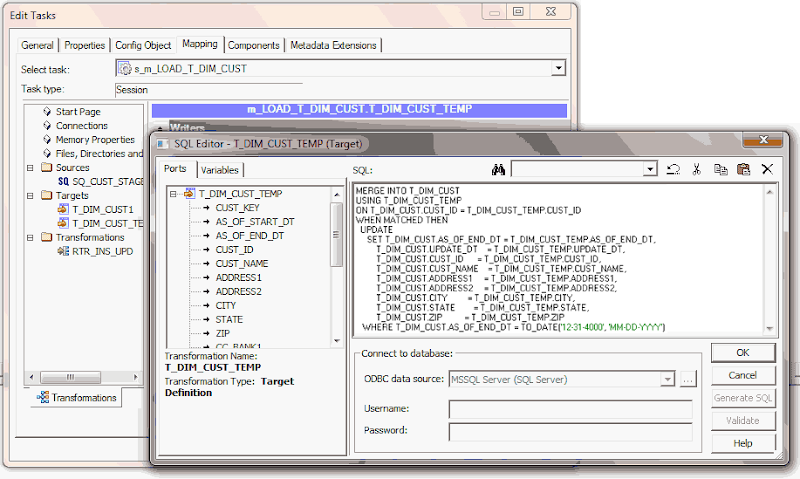
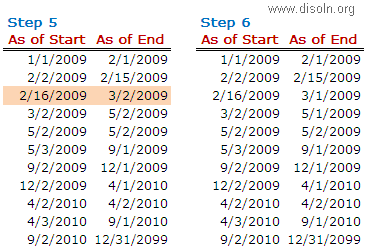
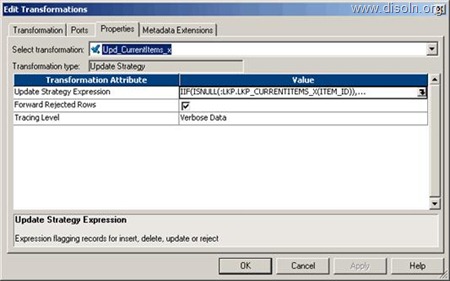
Now the mapping development is complete, during the session configuration process, add the below SQL as part of the Post session SQL statement as shown below. This MERGE INTO SQL will update the records in T_DIM_CUST table with the values from T_DIM_CUST_TEMP.
MERGEINTO T_DIM_CUST
USING T_DIM_CUST_TEMP
ON T_DIM_CUST.CUST_ID = T_DIM_CUST_TEMP.CUST_ID
WHENMATCHEDTHEN
UPDATE
SET T_DIM_CUST.AS_OF_END_DT = T_DIM_CUST_TEMP.AS_OF_END_DT,
T_DIM_CUST.UPDATE_DT = T_DIM_CUST_TEMP.UPDATE_DT,
T_DIM_CUST.CUST_ID = T_DIM_CUST_TEMP.CUST_ID,
T_DIM_CUST.CUST_NAME = T_DIM_CUST_TEMP.CUST_NAME,
T_DIM_CUST.ADDRESS1 = T_DIM_CUST_TEMP.ADDRESS1,
T_DIM_CUST.ADDRESS2 = T_DIM_CUST_TEMP.ADDRESS2,
T_DIM_CUST.CITY = T_DIM_CUST_TEMP.CITY,
T_DIM_CUST.STATE = T_DIM_CUST_TEMP.STATE,
T_DIM_CUST.ZIP = T_DIM_CUST_TEMP.ZIP
WHERE T_DIM_CUST.AS_OF_END_DT = TO_DATE('12-31-4000', 'MM-DD-YYYY')































![clip_image001[4]](http://lh6.ggpht.com/-tF08XGA9ApU/UVEQCPWwKFI/AAAAAAAAHp0/TCsqv0lZqB8/clip_image001%25255B4%25255D_thumb.png?imgmax=800 "clip_image001[4]")













![clip_image001[4]](http://lh5.ggpht.com/-6dcoUsj-8W8/UYchRquXfNI/AAAAAAAAH78/NRYg6jBfuY4/clip_image001%25255B4%25255D_thumb.png?imgmax=800 "clip_image001[4]")


![clip_image001[6]](http://lh4.ggpht.com/-uhKes7Qwpu0/UYchVIu8KzI/AAAAAAAAH9A/SaNVP5E2zFE/clip_image001%25255B6%25255D_thumb.png?imgmax=800 "clip_image001[6]")