![Informatica Performance Tuning Guide, Performance Enhancements - Part 4]()
Revisiting Change Data Capture (CDC)
When we talk about
Change Data Capture (CDC) in DW, we mean to capture those changes that have happened at the source side so far after we have run our job last time. In Informatica we call our ETL code as ‘Mapping’, because we MAP the source data (OLTP) into the target data (DW) and the purpose of running the ETL codes is to keep the source and target data in sync, along with some transformations in between, as per the business rules.
![SOFT and HARD Deleted Records and Change Data Capture in Data Warehouse]()
Now, data may get changed at source in three different ways.
- NEW transactions happened at source.
- CORRECTIONS happened on old transactional values or measured values.
- INVALID transactions removed from source.
Usually in our ETL we take care of the 1st and 2nd case(Insert/Update Logic); the 3rd change is not captured in DW unless it is specifically instructed in the requirement specification. But when it’s especially amended, we need to devise convenient ways to track the transactions that were removed i.e., to track the deleted records at source and accordingly DELETE those records in DW.
One thing to make clear is that Purging might be enabled at your OLTP, i.e OLTP keeping data for a fixed historical period of time, but that is a different scenario. Here we are more interested about what was DELETED at Source because the transactions was NOT valid.
Effects in DW for Source Data Deletion
DW tables can be divided into three categories as related to the deleted source data.
- When the DW table load nature is 'Truncate & Load' or 'Delete & Reload', we don't have any impact, since the requirement is to keep the exact snapshot of the source table at any point of time.
- When the DW table does not track history on data changes and deletes are allowed against the source table. If a record is deleted in the source table, it is also deleted in the DW.
- When the DW table tracks history on data changes and deletes are allowed against the source table. The DW table will retain the record that has been deleted in the source system, but this record will be either expired in DW based on the change captured date or 'Soft Delete' will be applied against it.
Types of Data Deletion
Academically, deleting records from DW table is forbidden, however, it’s a common practice in most DWs when we face this kind of situations. Again, if we are deleting records from DW, it has to be done after proper discussions with Business. If your Business requires DELETION, then there are two ways.
- Logical Delete :- In this case, we have a specific flag in the source table as STATUS which would be having the values as ‘ACTIVE’ or ‘INACTIVE’. Some OLTPs keep the field name as ACTIVE with the values as ‘I’, ‘U’ or ‘D’, where ‘D’ means that the record is deleted or the record is INACTIVE. This approach is quite safe and also known as Soft DELETE.
- Physical Delete :- In this case the record related to invalid transactions are fully deleted from the source table by issuing DML statement. This is usually done after thorough discussing with Business Users and related business rules are strictly followed. This is also known as Hard DELETE.
ETL Perspective on Deletion
When we have ‘Soft DELETE’ implemented at the source side, it becomes very easy to track the invalid transactions and we can tag those transactions in DW accordingly. We just need to filter the records from source using that STATUS field and issue an UPDATE in DW for the corresponding records. Few things to be kept in mind in this case.
If only ACTIVE records are supposed to be used in ETL processing, we need to add specific filters while fetching source data.
Sometimes INACTIVE records are pulled into the DW and moved till the ETL Data Warehouse level. While pushing the data into Exploration Data Warehouse, only the ACTIVE records are sent for reporting purpose.
For ‘Hard DELETE’, if Audit Table is maintained at source systems for what are transactions were deleted, we can source the same, i.e. join the Audit table and the Source table based on NK and logically delete them in DW too. But it becomes quite cumbersome and costly when no account is kept of what was deleted at all. In these cases, we need to use different ways to track them and update the corresponding records in DW.
Deletion in Data Warehouse : Dimension Vs Fact
In most of the cases, we see only the transactional records to be deleted from source systems. DELETION of Data Warehouse records are a rare scenario.
Deletion in Dimension Tables
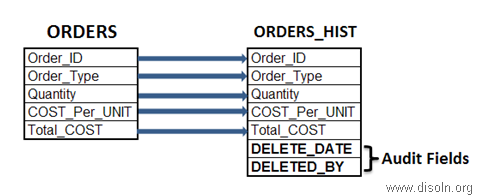
If we have DELETION enabled for Dimensions in DW, it's always safe to keep a copy of the OLD record in some AUDIT table, as it helps to track any defects in future. A simple DELETE trigger should work fine; since DELETION hardly happens, this trigger would not degrade the performance much.
Let's take this ORDERS table into consideration. Along with this, we can have a History table for ORDERS, e.g. ORDERS_Hist, which would store the DELETED records from ORDERS.
The below Trigger will work fine to achieve this.
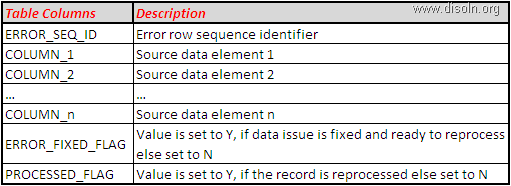
The AUDIT Fields will convey when this particular record was deleted and by which user. But this table needs to be created for each and every DW table where we want to keep the audit of what was DELETED. If the entire record is not need and only fields involved in Natural Key(NK) may work, we can have a consolidated table for all the Dimensions.
![SOFT and HARD Deleted Records and Change Data Capture in Data Warehouse]()
Here the Record_IDENTIFIER field contains the values of all the columns involved in the Natural Key(NK) separated by '#' of the table mentioned in the OBJECT_NAME field.
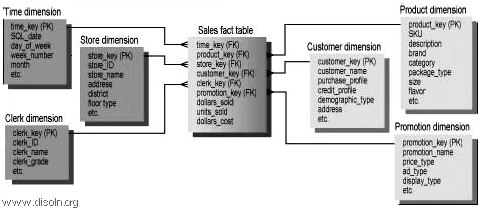
Sometimes, we face a situation in DW where a FACT table record contains a Surrogate Key(SK) from a Dimension but the Dimension table doesn't own it anymore. In those cases, the FACT table record becomes orphan and it will hardly be able to appear in any report since we always use the INNER JOIN between Dimensions and Fact while retrieving data in the reporting layer, and there it misses the Referential Integrity(RI).
Suppose, we want to track the orphan records from the SALES Fact table in respect of Product Dimension. We can use the query as below.
![]()
So, the above query will provide only the Orphan records, BUT certainly it cannot provide you the records DELETED from the PRODUCT_Dimension. So, one feasible solution could be while populating the EVENT table with the SKs from PRODUCT_Dimension that are being DELETED, provided we don't reuse our Surrogate Keys. So, when we have both the SKs and the NKs from the PRODUCT_Dimension in the EVENT table for DELETED entries, we can achieve a better compliance over the Data Warehouse data.
Another useful but least used approach is enabling the
audit for any table for DELETE in an Oracle DB using queries like the following.
Audit DELETE on SCHEMA.TABLE;
The table
DBA_AUDIT_STATEMENT will contain all the related details related to this deletion, example the user who issued the, exact DML statement and so on, but this cannot provide you with the record that was deleted. Since this approach cannot directly provide you information on which record was deleted, it’s not so useful in our current discussion, so I would like to keep aloof from the topic here.
Deletion in Fact Tables
Now, this was all about DELETION in DW Dimension tables. Regarding FACT data DELETION, I would like to cite an extract of what
Ralph Kimball has to say on Physical Deletion of Facts from DW.
Change Data Capture & Apply for 'Hard DELETE' in Source
Again, whether we should track the DELETED records from source or not depends on the type of table and its Load Nature. I will share few genuine scenarios that are usually faced in any DW and discuss about the solutions accordingly.
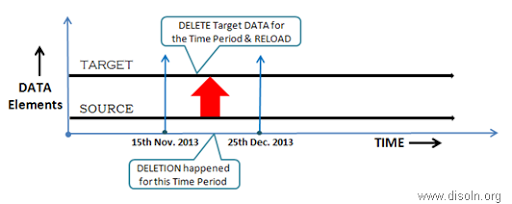
1. Records are DELETED from SOURCE for a known Time Period, no Audit Trail was kept.
In this case, the ideal solution is to DELETE the entire records’ set in DW for the Target table and pull the source records once again for the time period. This will bring the DW in sync with Source and DELETED records also will not be available in DW.
![SOFT and HARD Deleted Records and Change Data Capture in Data Warehouse]()
Usually time period is mentioned in terms of Ship_DATE or Invoice_DATE or Event_DATE, i.e. a DATE type field from the actual dataset of the source table is used, and hence the way we can filter the records for Extraction from source table using WHERE clause, we can do the same in DW table as well.
Obviously, in this case we are NOT able to capture the 'Hard DELETE' from the Source i.e., we cannot track the History of DATA, but we would be able to bring the Source and DW in sync at the least. Again, this approach is recommended only when the situation occurs once in a while and not on regular basis.
2. Records are DELETED from SOURCE on regular basis with NO Timeframe, no Audit Trail was kept.
The possible solution in this case would be to implement FULL Outer JOIN between the Source and the Target table. The tables should be joined on the fields involved in the Natural Key(NK). This approach will help us to track all three kinds of changes to source data in one shot.
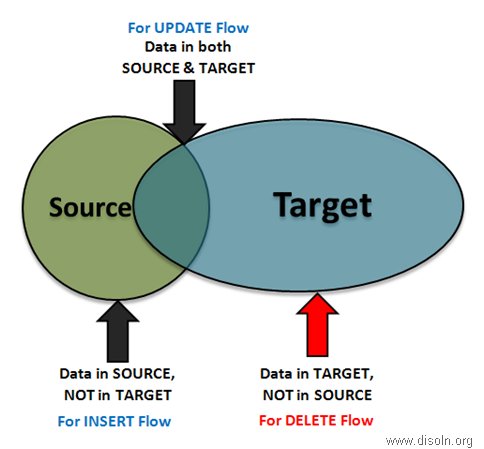
The logic can be better explained with the help of a Venn diagram.
Out of the Joiner (kept in FULL Outer Join mode),
- Records that have values for the NK fields only from the Source and not from the Target, they should go for the INSERT flow. These are all new records coming from source.
- Records that have values for the NK fields from both the Source and the Target, they should go for the UPDATE flow. These are already existing records of Source.
- Records that have values for the NK fields only from Target, will go for the DELETE flow. These are the records that were somehow DELETED from Source table.
Now, what we do with those DELETED records from Source, i.e. apply 'Soft DELETE' or 'Hard DELETE' in DW, depends on our requirement specification and business scenarios.
But this approach is having severe disadvantage in terms of ETL Performance. Whenever we go for a FULL Outer JOIN between Source and Target, we are using the entire data set from both the ends and this will obviously obstruct the smooth processing of ETL when data volume increases.
3. Records are DELETED from SOURCE, Audit Trail was kept.
Even though I'm mentioning it a DELETION, it's NOT the kind of Physical DELETION that we discussed previously. This is mainly related to incorrect transactions in Legacy Systems, e.g. Mainframes, which usually send data in flat files.
When some old transactions become invalidated, source team sends those transactions related records again to DW but with inverted measures, i.e. the sales figure are same as the old ones but they are negative. So, DW contains both the old set of records and the newly arrived records, but the aggregated measures become NULL in the aggregated FACT table, thus diminishing the impact of those invalid transactions in DW to NULL.
Only disadvantage of this approach is, Aggregated FACT contains the correct data at the summarized level, but the transactional FACT dual set of records, which together
About the Author
represent the real scenario, i.e. at first the transaction happened(with the older record) and then it became invalid(with the newer record).
Hope you guys enjoyed this article and gave you some new insights into change data capture in Data Warehouse. Leave us your questions and commends. We would like to hear how you have handled change data capture in your data warehouse.






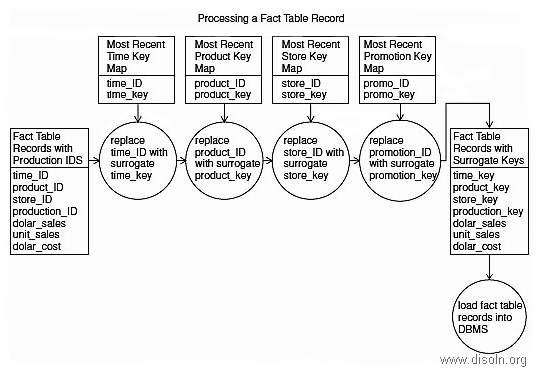
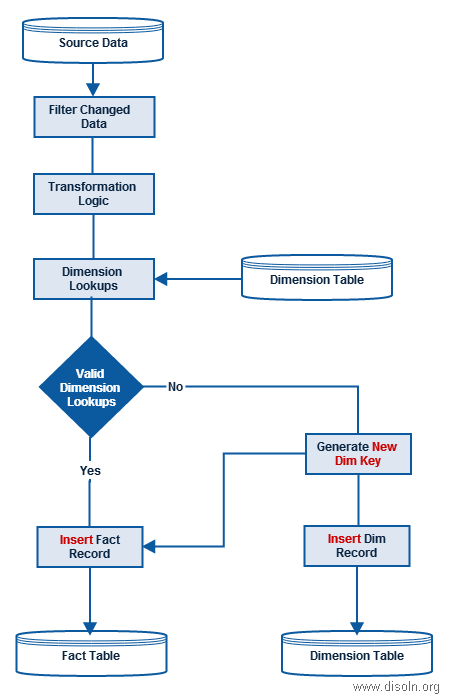
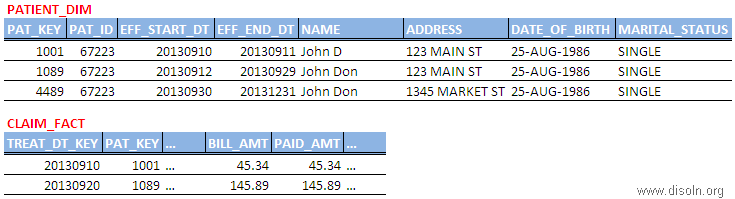
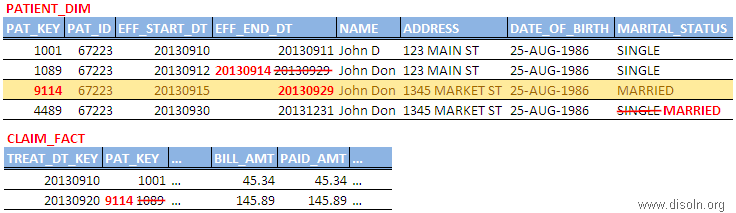
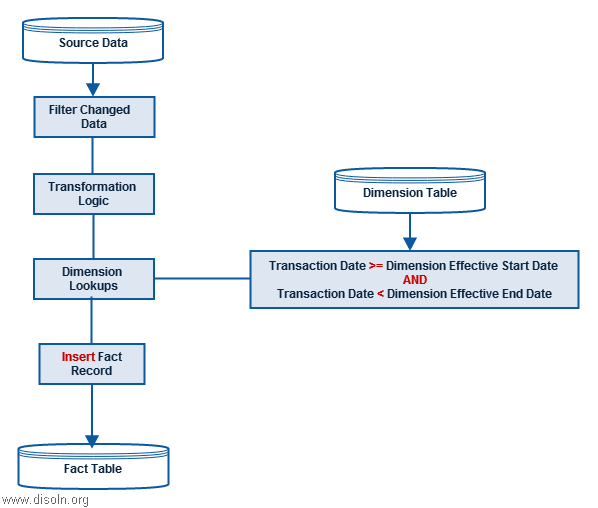
 Surrogate keys are widely used and accepted design standard in data warehouses. It is sequentially generated unique number attached with each and every record in a Dimension table in any Data Warehouse. It join between the fact and dimension tables and is necessary to handle changes in dimension table attributes.
Surrogate keys are widely used and accepted design standard in data warehouses. It is sequentially generated unique number attached with each and every record in a Dimension table in any Data Warehouse. It join between the fact and dimension tables and is necessary to handle changes in dimension table attributes.